
an Empirical Survey from the Data Fitness Perspective
Motivation
Graphs, particularly knowledge graphs, have garnered significant attention lately, primarily due to their ability to mitigate the problem of data hallucination. In our increasingly complex world, accurately modeling this complexity is crucial. Graphs provide a powerful framework for representing and understanding intricate relationships among data entities. Applications such as recommendation systems and Google’s knowledge graph-driven search exemplify the practical utility of graphs in various domains.
Despite the advantages of graphs, effectively computing and utilizing them in computational tasks pose significant challenges. Graph structures inherently entail complexity, making it difficult to process and derive insights from them directly. Hence, there arises a need to translate these complex structures into formats that align with conventional computational paradigms.
Graph embedding, as well as knowledge graph embedding, emerges as a solution to bridge the gap between complex graph structures and conventional tabular format. By embedding graphs into lower-dimensional vector spaces, we can represent graph entities and their relationships in a format we are familiar with. Node2vec is one of the powerful graph emebedding algorithms.
In domains rich in structural information, the standard procedure typically involves constructing a graph representation of the data and extracting node features. Subsequently, graph embedding or knowledge graph embedding algorithms are applied to this graph, with the expectation that these techniques will effectively capture both the inherent structure of the data and the informative features associated with each node. The overarching goal is to enable the model to seamlessly integrate structural and feature information, and then benefit the following tasks. The process is shown in below picture.
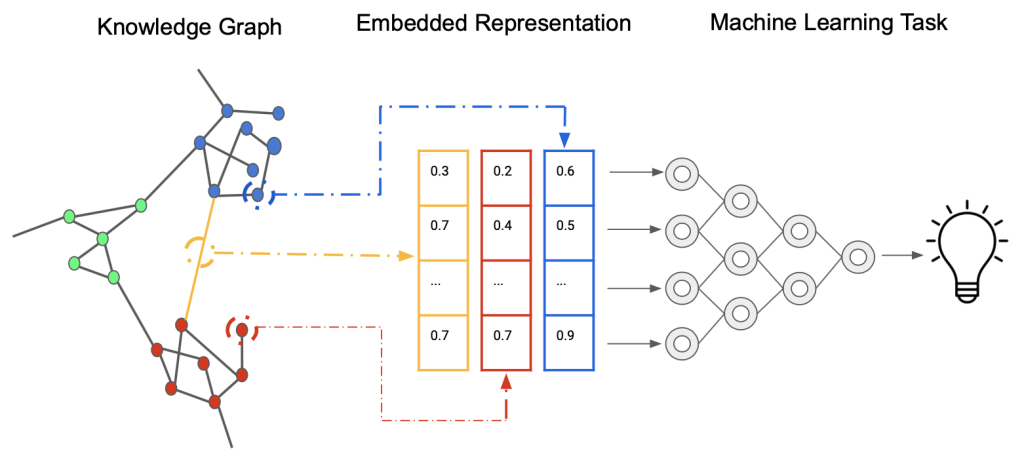
Indeed, the diversity among graph types poses a significant challenge in developing a unified embedding model that caters to all domains. Each graph, whether it’s a knowledge graph, a traffic network, a social network, or a citation network, exhibits unique characteristics and complexities. This diversity necessitates specialized embedding techniques tailored to specific graph types. However, current research lacks definitive guidance on which embedding techniques are most suitable for particular graph domains. As a result, there remains a gap in understanding which methods are optimal for capturing the structural and feature information inherent in different graph types. Addressing this gap is crucial for advancing graph-based methodologies and unlocking their full potential across diverse applications.
This leads to our research question:
- Q1. Is there a potential benefit of applying graph representation learning?
- Q2. Is structural information alone sufficient?
- Q3. Which embedding technique would best suit my dataset?
Some thoughts
Graphs, at first glance, seem simple enough, right? But delve deeper, and you’ll find they’re a bit like Pandora’s box – full of complexities waiting to be unraveled. Let’s take a closer look at this intriguing concept:
- For mathematicians, graphs have their own special flavor. They talk about graph embedding, which isn’t quite the same as what we’re discussing here.
- Then there’s the realm of network science, where the goal is to decode the intricate structures of our real-world connections. Websites like http://networksciencebook.com/ are dedicated to this pursuit.
- And let’s not forget knowledge graphs – our attempt to organize information in a graph-like fashion.
It’s like we’re all on a quest to conquer the graph, but each of us sees it through a different lens. Despite the similarities, there are significant differences lurking beneath the surface.
No one really claims mastery in this field – it’s just too darn complex. And trying to neatly categorize the different types of graphs and networks? I wouldn’t even attempt it.
But here’s the thing: this lack of clarity can really slow us down. Let me give you an example. Say I want to use knowledge graph embedding to tackle traffic networks. It sounds promising, right? But when it comes to putting it into practice in the real world? Well, that’s a whole different story.
And let’s not overlook the difference between knowledge graphs packed with numerical data and those overflowing with semantics. They might seem similar, but trust me, they call for completely different approaches.
This actually call for more effort in this area, to draw a clear line, for the graph network required the information flow, like the social and traffic network, GCN or GraphSAGE may be a good direction. However, Knowledge graph probably call for TransE like ways.
Our research
This leads to our research, we try to understand for node classification tasks within graph, for different types of the graph, which network metrics/measurements will indicates which algorithms will be suitable for you.

Presentation in PAKDD2024
What we have done
- Gather a list of graph datasets
- Select 13 network characterics measurements
- Select 4 representive graph embedding algorithms
- Running the node classification task with different approaches.
- Compare the model performance matrix with the network characistics matrix
- Looking for the key indicator in network characterics affects the model performance
We find out it is
- Number of edges
- Number of classes
- Diameter or Average Shortest Path
Will affect the graph embedding models performance for node classification tasks.
Presentation Notes
Github Link
https://github.com/PascalSun/PAKDD-2024
Citation
@InProceedings{10.1007/978-981-97-2253-2_32,
author="Sun, Qiang
and Huynh, Du Q.
and Reynolds, Mark
and Liu, Wei",
editor="Yang, De-Nian
and Xie, Xing
and Tseng, Vincent S.
and Pei, Jian
and Huang, Jen-Wei
and Lin, Jerry Chun-Wei",
title="Are Graph Embeddings the Panacea?",
booktitle="Advances in Knowledge Discovery and Data Mining",
year="2024",
publisher="Springer Nature Singapore",
address="Singapore",
pages="405--417",
abstract="Graph representation learning has emerged as a machine learning go-to technique, outperforming traditional tabular view of data across many domains. Current surveys on graph representation learning predominantly have an algorithmic focus with the primary goal of explaining foundational principles and comparing performances, yet the natural and practical question ``Are graph embeddings the panacea?'' has been so far neglected. In this paper, we propose to examine graph embedding algorithms from a data fitness perspective by offering a methodical analysis that aligns network characteristics of data with appropriate embedding algorithms. The overarching objective is to provide researchers and practitioners with comprehensive and methodical investigations, enabling them to confidently answer pivotal questions confronting node classification problems: 1) Is there a potential benefit of applying graph representation learning? 2) Is structural information alone sufficient? 3) Which embedding technique would best suit my dataset? Through 1400 experiments across 35 datasets, we have evaluated four network embedding algorithms -- three popular GNN-based algorithms (GraphSage, GCN, GAE) and node2vec -- over traditional classification methods, namely SVM, KNN, and Random Forest (RF). Our results indicate that the cohesiveness of the network, the representation of relation information, and the number of classes in a classification problem play significant roles in algorithm selection.",
isbn="978-981-97-2253-2"
}
Our paper link
https://link.springer.com/chapter/10.1007/978-981-97-2253-2_32

