
Unified Knowledge Graph Construction from Heterogeneous Documents Assisted by Large Language Models
Even with a conservative estimate, 80% of enterprise data is stored in unstructured files within data lakes that contain various formats. Traditional search engines can no longer meet the needs for information seeking, especially when the task involves browsing and exploring to gain insights without clear search keywords.
Large Language Models (LLMs) and Retrieval Augmented Generation (RAG) offer a solution to this problem. RAG currently splits and embeds documents, then performs a semantic similarity search to retrieve relevant content. However, this approach can lead to an information cocoon problem. For example, if you want to understand the profit from the last financial year, your question will retrieve the profit report but may not provide information on why the profit increased or decreased, as this information might be in sections before or after the profit section within your report document, and the content there may not have high semantic similarity with your question.
In such cases, both the document’s layout structure and semantics are equally important when using LLMs to answer exploratory tasks where you may not know exactly what you want to find out.
To address this, we developed a open source package called Docs2KG, which will build a multimodal knowledge graph with dual aspects: one aspect represents the structural relationships within the documents, and the other represents the semantic relationships. Using this foundation, we can implement GraphRAG, a method proposed by Microsoft, to achieve better results, especially for exploratory questions.
Installation
We have published the package to PyPi: Docs2KG,
You can install it via:
pip install Docs2KG
Tutorial
We have a demonstration to walk through the components of Docs2KG.
The downstream usage examples is also included.
Video is available at Demo Docs2KG
The tutorial details is available at Tutorial Docs2KG
Which includes:
- How to get started with Docs2KG?
- How to process the documents with Docs2KG?
- Modules in Docs2KG?
- How to construct the unified multimodal knowledge graph?
- How to load the unified multimodal knowledge graph into the GraphDB?
- How to further enhance the unified multimodal knowledge graph?
- How to use the unified multimodal knowledge graph in downstream applications?
We also provide the Example Codes in Example Codes Docs2KG
The source codes documentation is available at Docs2KG Documentation
Motivation
Three pillars of the LLM applications in our opinion:
- Data
- RAG
- LLM
Most of the tools in the market nowadays are focusing on the Retrieval Augmented Generation (RAG) pipelines or How to get Large Language Models (LLMs) to run locally.
Typical tools include: Ollama, LangChain, LLamaIndex, etc.
However, to make sure the wider community can benefit from the latest research, we need to first solve the data problem.
The Wider community includes personal users, small business, and even large enterprises. Some of them might have developed databases, while most of them do have a lot of data, but they are all in unstructured form, and distributed in different places.
So the first challenges will be:
- How can we easily process the unstructured data into a centralized place?
- What is the best way to organize the data within the centralized place?
Proposed Solution
This package is a proposed solution to the above challenges.
- We developed the tool for the wider community to easily process the unstructured data into a centralized place.
- We proposed a way to organize the data within the centralized place, via a Unified Multimodal Knowledge Graph altogether with semi-structured data.
Given the nature of unstructured and heterogeneous data, information extraction and knowledge representation pose significant challenges. In this package, we introduce Docs2KG, a novel framework designed to extract multi-modal information from diverse and heterogeneous unstructured data sources, including emails, web pages, PDF files, and Excel files. Docs2KG dynamically generates a unified knowledge graph that represents the extracted information, enabling efficient querying and exploration of the data. Unlike existing approaches that focus on specific data sources or pre-designed schemas, Docs2KG offers a flexible and extensible solution that can adapt to various document structures and content types. The proposed framework not only simplifies data processing but also improves the interpretability of models across diverse domains.
Overall Architecture
The overall architecture design will be shown in:
The data from multiple sources will be processed by the Dual-Path Data Processing. Some of the data, for example, the exported PDF files, Excel files, etc., they can be processed and handle by programming parser. So it will be converted generally into the markdown, and then transformed into the unified knowledge graph. For data like scanned PDF, images, etc., we will need the help from Doc Layout Analysis and OCR to extract the information, then we will convert the extracted information into the markdown, and then transformed into the unified knowledge graph.
Then the unified multimodal knowledge graph will be generated based on the outputs:
- Text
- Markdown
- Text2KG Output
- Table CSV
- Table Image
- Image
The unified multimodal knowledge graph will have mainly two aspects:
- Layout Knowledge Graph
- The layout of the documents are helping us to understand the structure of the documents.
- So it will be also necessary and important represented within the unified multimodal knowledge graph.
- Semantic Knowledge Graph
- The semantic connections are the part our brain will be interested in when we read the documents.
- So with the help of the LLM, we can try to extract the semantic connections from the documents.
- Which can help human to understand the documents better from the semantic perspective.
Implemented System Architecture
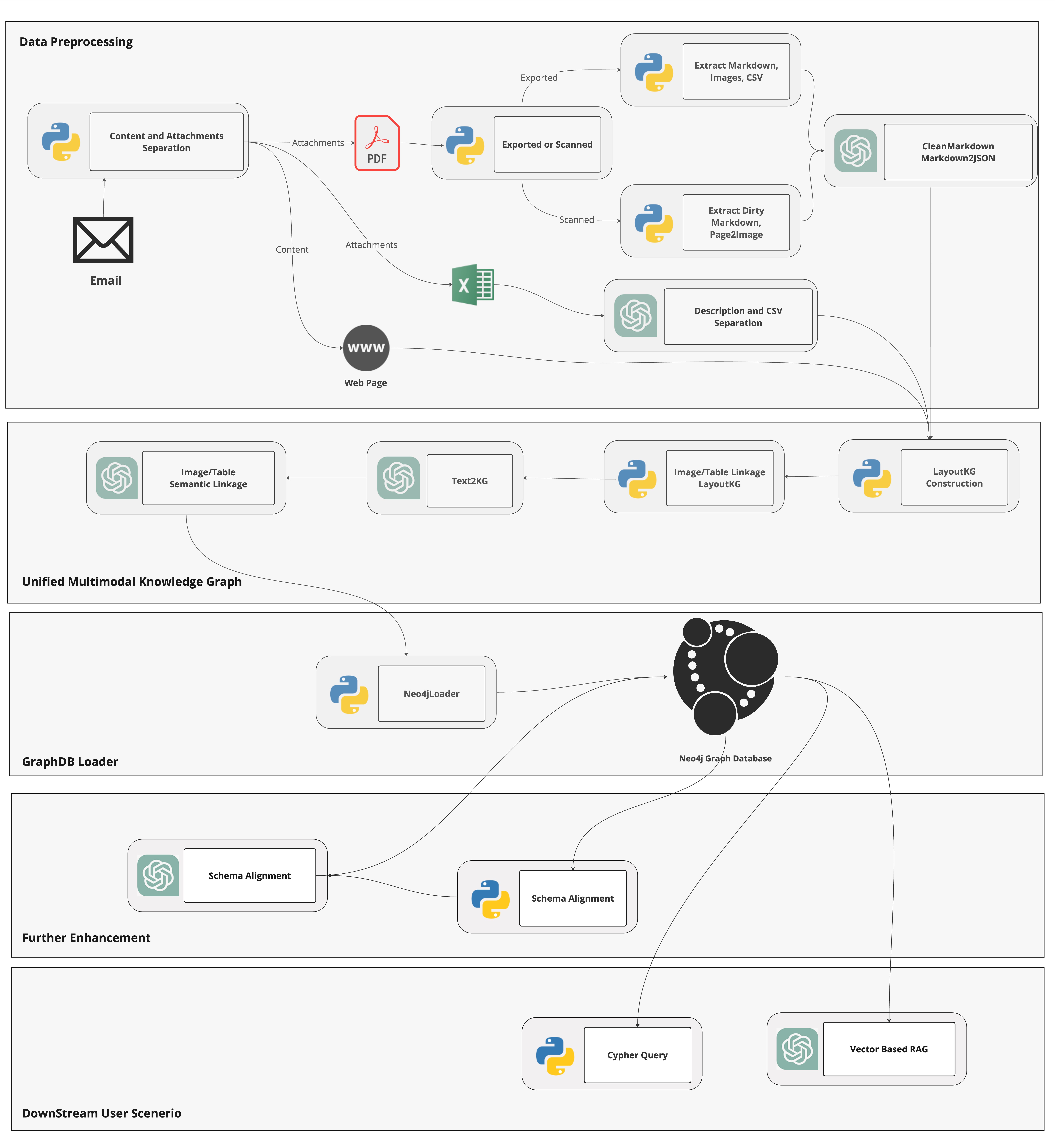
The overall steps include:
- Data Processing
- Dual-Path Data Processing
- Get the documents from diverse sources with diverse formats into Markdown, CSV, JSON, etc.
- Unified Multimodal Knowledge Graph Construction
- GraphDB Loader
- Load the unified multimodal knowledge graph into the GraphDB
- We use Neo4j as the GraphDB in this project
- Further Enhancement
- The KG schema is generated and dynamic, and will not be perfect at the beginning.
- So we need to further enhance the KG schema
- Via automatic schema merge: node label frequency based merge, label semantic similarity based merge
- Via human in the loop: human review and further enhance the KG schema
- Downstream Applications
- Traditional Cypher Query: NLP Query to Cypher Query (Can with help from LLM)
- Vector Based RAG:
- Get the embedding of each node first.
- Then use the embedding of the query to do the similarity search to extract the anchor nodes within the graph.
- Use these nodes as the anchor nodes, doing multi hop information extraction to augment the query.
- Use LLM to do the final generation based on the augmented query.
Setup and Development
python3 -m venv venv
source venv/bin/activate
pip install -r requirements.txt
pip install -r requirements.dev.txt
pip install -e .Citation
If you find this package useful, please consider citing our work:
@misc{sun2024docs2kg,
title={Docs2KG: Unified Knowledge Graph Construction from Heterogeneous Documents Assisted by Large Language Models},
author={Qiang Sun and Yuanyi Luo and Wenxiao Zhang and Sirui Li and Jichunyang Li and Kai Niu and Xiangrui Kong and Wei Liu},
year={2024},
eprint={2406.02962},
archivePrefix={arXiv},
primaryClass={cs.CL}
}

